{kind=link}
{kind=link}
{kind=link}
vídeo: https://youtu.be/HSZ_uaif57o
Quando você faz uma pergunta ela precisa ser traduzida em um formato que a IA entenda: os embeddings, sinônimo de vetores, que é um conceito matemático e significa colocar um objeto em um espaço diferente.
Note
Os modelos de aprendizado de máquina usam vetores (matrizes de números) como entrada. Ao trabalhar com texto, a primeira coisa que você deve fazer é criar uma estratégia para converter strings em números (ou "vetorizar" o texto) antes de alimentá-lo ao modelo. https://www.tensorflow.org/text/guide/word_embeddings?hl=pt-br
Na prática uma palavra como "hello word", supondo que sejam representados por vetores de 1536 dimensões (quantidade que os modelos open source utilizam), seriam representados assim:
- "hello": [0.12, 0.25, ..., 0.87]
- "world": [0.34, 0.44, ..., 0.56]
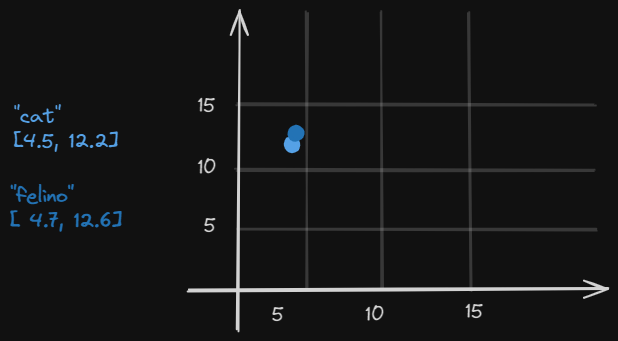
Isso seria sua posição em um vetor. Neste outro exemplo mais simplista, podemos ver a semelhança do significado das palavras "cat e "felino" com sua representação dos vetores em um diagrama:
Tendo isto em mente, os algoritmos de modelos de aprendizado de máquina realizam um cálculo de aritmética vetorial. Temos as palavras "king" (2, 5), "man" (1, 3) e "woman" (1, 4). Quero o significado da palavra king, remover o contexto da palavra man e adicionar a palavra woman:
(2, 5) - (1, 3) + (1, 4) = (2, 6)
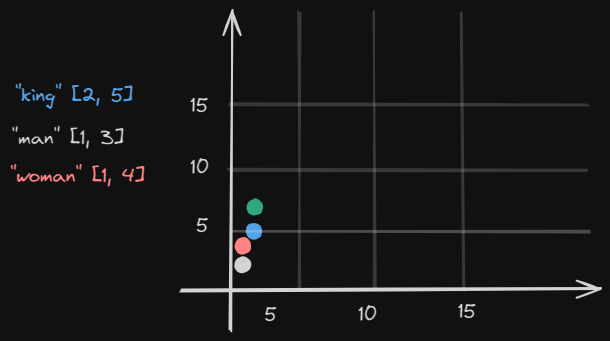
Imaginando que exista a palavra "queen" na posição (2, 6.2) esta seria o significado que o algoritmo iria utilizar em sua resposta.
Note
Por que isso é útil? Depois de gerarmos incorporações em vários textos, é trivial calcular o quão semelhantes eles são usando operações matemáticas vetoriais como distância de cosseno. Um caso de uso perfeito para isso é a pesquisa. Seu processo pode ter a seguinte aparência:
- Pré-processe sua base de conhecimento e gere incorporações para cada página
- Armazene suas incorporações para serem referenciadas posteriormente (mais sobre isso)
- Criar uma página de pesquisa que solicite a entrada do usuário
- Receba a entrada do usuário, gere uma incorporação única e execute uma pesquisa de similaridade em relação às incorporações pré-processadas.
- Retornar as páginas mais semelhantes para o usuário
- Getting Started With Embeddings (huggingface.co)
- Embeddings de Palavras | TensorFlow Core
- Embeddings | Machine Learning | Google for Developers
- Introdução a incorporações de texto e código | OpenAI
- Machine Learning | Google for Developers
- The Official LangChain.js Course (scrimba.com)
- Learn AI Agents (scrimba.com)
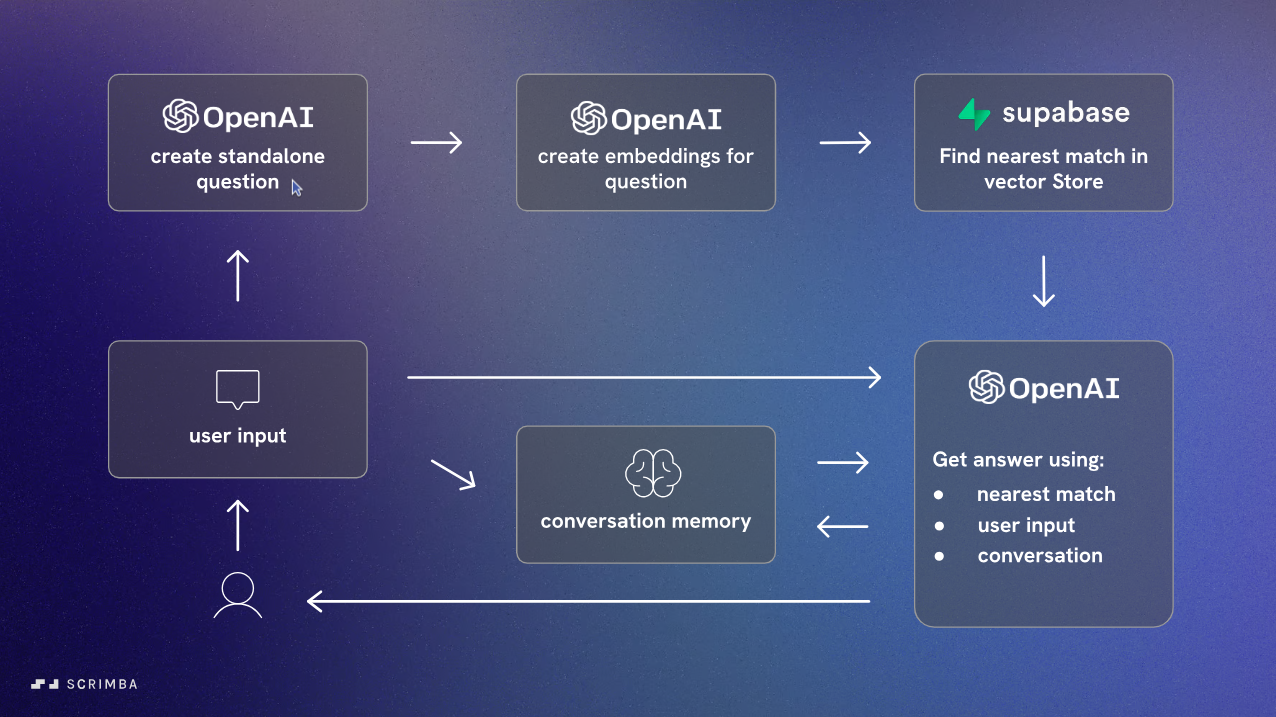
A imagem descreve um fluxo de respostas a perguntas do usuário usando OpenAI + Lanchain + Supabase
- Input do Usuário
- A pergunta do usuário é reformulada para ficar mais direta, sem a necessidade de contexto adicional.
import { ChatOpenAI } from "langchain/chat_models/openai";
import { PromptTemplate } from "langchain/prompts";
- É gerado os embeddings da pergunta reformulada
import { OpenAIEmbeddings } from 'langchain/embeddings/openai';
- Encontrar a Correspondência Mais Próxima nos Vetores armazenados no Supabase
import { createClient } from '@supabase/supabase-js';
import { SupabaseVectorStore } from 'langchain/vectorstores/supabase';
- A resposta é gerada usando a Correspondência Mais Próxima + Entrada do Usuário + O histórico da conversa
import { ConversationalRetrievalQAChain } from 'langchain/chains';
- A memória da conversa é atualizada com a nova interação
import { ConversationMemory } from 'langchain/memory';